최근 몇 달간 YOLO를 이용한 Vision+AI+IoT 프로젝트를 진행하고 있다.
다행히 큰 무리(?) 없이 프로젝트를 종료하는 과정에 있고, 그중 몇 가지를 지식 공유 + 컨텐트 정리를 위해 기록하려고 한다.
YOLO에 대한 논문은 워낙 유명하여 관련 자료를 쉽게 찾을 수 있는데, 오히려 YOLO를 사용해 보기 위해 환경을 구성하고 샘플을 돌려보는 과정이 진입장벽이 되곤 한다. 프로젝트에서는 Visual Studio, GCC 를 이용해서 소스코드를 컴파일해서 활용했지만, 아무래도 파이썬을 이용하는 것이 좀 더 빠르고 쉽게 YOLO를 확인해 볼 수 있을 것 같다.
서론은 이만하고, 빠르게 내용을 정리한다.
환경 준비
- Anaconda : 머신러닝, 데이터 분석을 위해 미리 설치해 놓았기에 사용하는 것으로 꼭 필요한 것은 아니다.
- 파이선 3.8을 기준으로 개발/테스트 환경을 구성한다. (Anaconda를 사용하지 않고 Python의 virtualenv 등을 이용해도 된다.)
- conda create -n YOLO python=3.7
- conda activate YOLO
필요한 Python Package 설치
- pip install tensorflow (GPU 버전인 tensorflow-gpu 를 이용할 수도 있다.)
- pip install opencv-python
- pip install easydict
- pip install pillow
YOLOv4 (Python) 소스코드 다운로드 (git을 이용한다.)
- git clone https://github.com/hunglc007/tensorflow-yolov4-tflite
YOLOv4 weight 파일을 다운로드한 후 tensorflow 버전으로 변환한다.
- YOLOv4 weght 파일은 인터넷으로 검색한 후 다운로드하였다.

- tensorflow-yolov4-tflie 폴더에 있는 'save_model.py'를 이용하여 변환한다.
- python save_model.py --weights ../yolov4.weights --output ./checkpoints/yolov4-416 --input_size 416 \
--model yolov4
- python save_model.py --weights ../yolov4.weights --output ./checkpoints/yolov4-416 --input_size 416 \

함께 제공된 이미지 파일을 이용하여 이미지 내 객체를 확인해 본다.
- 전체 옵션을 지정하여 확인해 볼 수도 있고, 기본(default) 옵션을 이용할 수도 있다.
- python detect.py --weights ./checkpoints/yolov4-416 --size 416 --model yolov4 --image ./data/kite.jpg
- python detect.py (이미지를 지정하지 않으면, kite.jpg를 이용한다.)

- 샘플로 제공되는 girl.png를 이용해 본다.
- python detect.py --image ./data/girl.png

함께 제공된 동영상 파일을 이용하여 동영상 내 객체를 확인해 본다.
- 전체 옵션을 지정하여 확인해 볼 수도 있고, 기본(default) 옵션을 이용할 수도 있다.
- python detectvideo.py --weights ./checkpoints/yolov4-416 --size 416 --model yolov4 --video ./data/road.mp4
- python detectvideo.py (동영상을 지정하지 않으면 road.mp4를 기본으로 이용한다.)

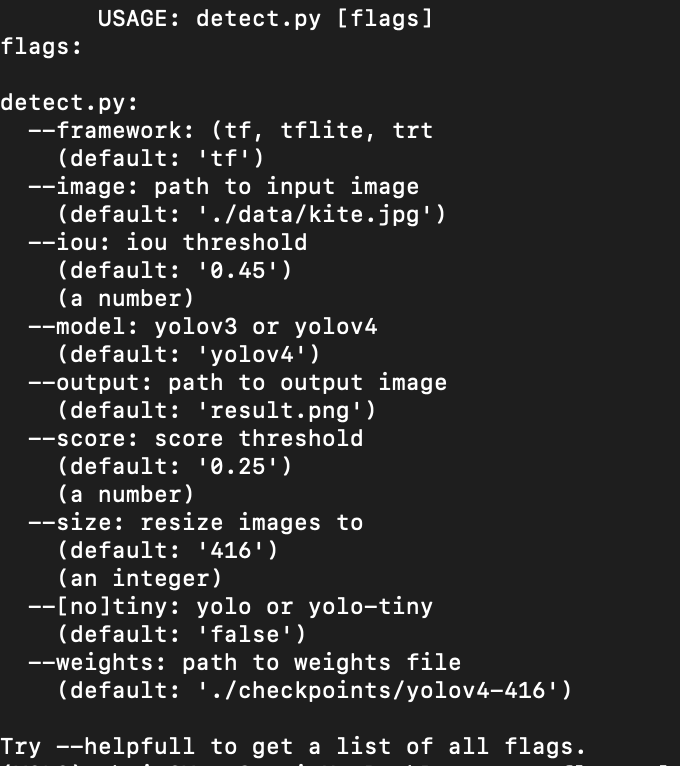
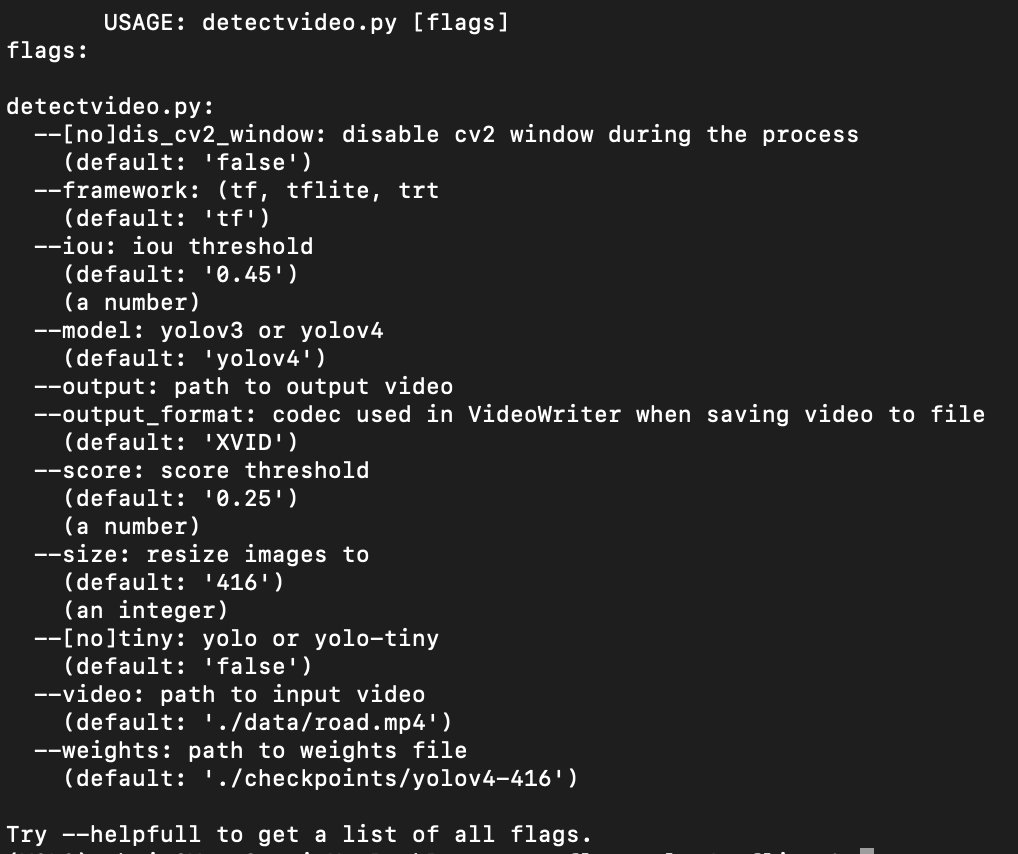
참고 삼아, 사용할 수 있는 옵션을 확인해 본다.
- --help 를 이용하여 이용할 수 있는 옵션을 확인할 수 있다.
- python detect.py --help
- python detectvideo.py --help
마지막으로 '어떤 객체가 확인(detect)'되었는지 코드 내에서 점검할 수 있는 방법을 살펴보았다.
- /core/utils.py의 draw_bbox() 함수를 살펴보자.
- 153 line을 보면, 결과 이미지에 검출한 객체 정보를 그리는 루틴이 있다.
- 관련 정보를 이용하여 다음과 같은 함수를 추가한다.
...
c1, c2 = (coor[1], coor[0]), (coor[3], coor[2])
cv2.rectangle(image, c1, c2, bbox_color, bbox_thick)
# 추가한 것은 아래 print()문이다.
print('Check => %s (%d, %d, %d, %d)' % (classes[class_ind], coor[0], coor[1], coor[2], coor[3]))
...- 이제 다시 detect.py를 실행하여 콘솔에 표시되는 print() 문을 확인한다.
- python detect.py

Check => person (695, 213, 860, 270)
Check => kite (79, 588, 154, 672)
Check => person (613, 113, 764, 165)
Check => kite (343, 577, 367, 600)
Check => person (487, 344, 504, 356)
Check => kite (236, 279, 279, 306)
Check => person (504, 518, 526, 534)
Check => person (511, 32, 555, 57)
Check => person (508, 80, 567, 107)
Check => kite (339, 468, 357, 485)
Check => person (538, 177, 576, 193)
Check => kite (393, 1083, 424, 1101)
Check => kite (375, 305, 397, 327)
Check => person (517, 533, 531, 552)
Check => person (451, 1205, 462, 1215)
Check => kite (377, 761, 391, 771)
- 이렇게 이미지 내에서 탐지된 정보를 확인할 수 있으니, 이것을 활용하여 특정 객체의 탐지 여부와 관련 정보를 확인할 수 있고, YOLO를 이용한 프로그램(서비스) 구현에 참고할 수도 있다.
이미 만들어진 Weight 파일이 아닌 '특정 이미지를 대상으로 YOLO를 이용'하려는 경우, 태깅한 이미지(학습셋)을 이용하여 별도의 Weight 파일을 만들고 사용해야 한다.
이에 대한 내용은 다음회차에~~
ps) 많은 분들이 오픈소스로 좋은 내용을 공유하고 계시니, 오픈소스 기여자 분들께 감사를 드린다. ^^*
'DevSmile 하는 일 > 데이터분석-인공지능-자동화' 카테고리의 다른 글
| AI딥러닝 실무 - LLM, 생성형 AI에 대해 정리한다. (0) | 2024.05.06 |
|---|---|
| 2학기 강의 - AI딥러닝실무를 시작한다. (0) | 2024.04.24 |
| [수학] 데이터 분석을 본격적으로 공부해 보려 한다. (0) | 2020.01.03 |
| [파이썬] 이미지에서 텍스트 추출하기 - tesseract (0) | 2019.11.18 |
